
On BERT for non-English, finding data, and the fine art of web-scraping
Published on Oct 07, 2020 by Impaktor.
One person’s data is another person’s noise.
K. C. Cole
Table of Contents
- 1. Introduction
- 2. Data sources for non-English sentiment analysis
- 3. Web scraping
- 4. Tokenizers
- 5. Learning BERT (PyTorch only)
- 6. Non-English BERT
- 7. TODO Pre-training BERT (training from scratch)
- 8. Beyond BERT
1. Introduction
Documentation of my exploration for learning BERT (Bidirectional Encoder Representations from Transformers), and finding multi-language sources for training BERT language model, and fine tuning. Specifically, to train a transformer model for Norwegian language (bokmål), preferably BERT, but methods and data sources are applicable to many other non-standard languages.
2. Data sources for non-English sentiment analysis
Collection of data resources for training sentiment analysis, or simply just raw text for training language model, like BERT.
2.1. Multilanguage source (incl. Norwegian)
General advice to find raw text corpus in your language, look up:
- NLP groups in universities of your country. What have they done?
- NLP projects in the national/royal library. Have they compiled any corpus?
- NLP projects in prominent book/news publishing houses.
- Transcripts of speeches and/or proceedings from parliament/bureaucracy of your country or public administration documents
Specific multilanguage sources:
- Leipzig Corpora Newspaper texts or texts randomly collected from the web,
foreign sentences removed
- 10,000 sentences up to 1 million sentences: download norwegian
- Open subtitles, in total 62 languages, 22G tokens: here, with parser for downloading and extracting tokens into one corups:
- TenTen Corpus Family Corpus for 40 langauges, targets +10 billion words per language, text from web, 2.47 billion words, in bokmål. Source is from a “linguistically valuable corpus” curated from web content.
- TalkOfEurope Project from 2016, that covers all plenary debates held in the European Parliament (EP) between 1999-07 – 2014-01. Access to data here (2.4GB compressed).
- Tatoeba collection of sentences and translations. Their default
sentence.csvdataset consists of 8M sentences (500MB), in various languages. Used by Facebook research in their LASER paper, their processed data in github here. - Common Crawl web crawl data, from +40 languages supported, released monthly. ~ 250 TB of data stored on AWS in WARC format, from billions of web pages. Note: might need substantial cleaning for pre-training BERT. See examples to get started. (Disclaimer: I have not worked with this data set myself).
OSCAR Open Super-Large Crawl Data, for many languages, see table.
Table 1: Example of some of the data from OSCAR that is of interest to me Language Words original Size original Words deduplicated Size deduplicated Norwegian 1,344,326,388 8.0G 804,894,377 4.7G Norwegian Nynorsk 14,764,980 85M 9,435,139 54M Swedish 7,155,994,312 44G 4,106,120,608 25G Finnish 3,196,666,419 27G 1,597,855,468 13G Danish 2,637,463,889 16G 1,620,091,317 9.5G Esperanto 48,486,161 299M 37,324,446 228M English 418,187,793,408 2.3T 215,841,256,971 1.2T French 46,896,036,417 282G 23,206,776,649 138G
- Project Gutenberg: based on 3000 books in English, but worth investigating if there’s something similar for other languages as well?
- Wikipedia-dumps, plus wiki-extractor.py. Note see warning about using wikipedia data further down.
- WikiText the source which multilanguage BERT is trained on. 100M tokens, 110 times larger than Penn Treebank (PTB) (Or is this English only?)
- Homemade BookCorpus Are there non-English books in this data set of 200k books in raw txt?
Other
- conceptnet-numberbatch The best pre-computed word embeddings you can use, word embeddings in 78 different langauges.
2.2. Norwegian specific sources
- NoReC: The Norwegian Review Corpus 15M tokens, 35.2k full text reviews scored 1-6, from newspapers 2003–2017, created by the SANT project. The data is stored in CoNNL-U format. This can be read from python using following options:
- talk-of-norway Norwegian Parliament Corpus 1998–2016, with both metadata, and raw text from speeches.
- noTenTen: Corpus of the Norwegian Web, 2.47 billion words (bokmål), 44 million (nynorsk).
- bokelskere.no, has book review dataset (local goodreads.com equivalent), about 180k reviews, however, only 20% have set a score.
- www.legelisten.no site for doctor, psychiatrist, and dentist reviews. I’ve scraped this manually (47000 reviews, from 4400 unique doctors, as of 2020-09) data not provided, method described further down.
- Språkbanken from Nasjonalbiblioteket, Looks to have many resources, need to lookinto it.
- Aftenposten archive with more than 150 year worth of articles. Requires account on aftenposten, and perhaps/likely not in “raw” format, perhaps one can buy a data-dump from them?
- Norwegian NLP Resources github readme with collection of NLP resources for Norwegian NLP. Great resource.
- Wikipedia.no Norwegian wikipedia, (maybe use wikiextractor).
- Other resources, e.g. Research groups at University in Oslo (UiO):
- Language Technology Group (LTG), NLP research group at Oslo University.
- Sentiment Analysis for Norwegian Text (SANT). Research group behind the NoReC data set,
- Evaluating semantic vectors for Norwegian (Master thesis)
2.3. Warning about training on Wikipedia
A word of caution when training on wikipedia text, illustrated by example below:
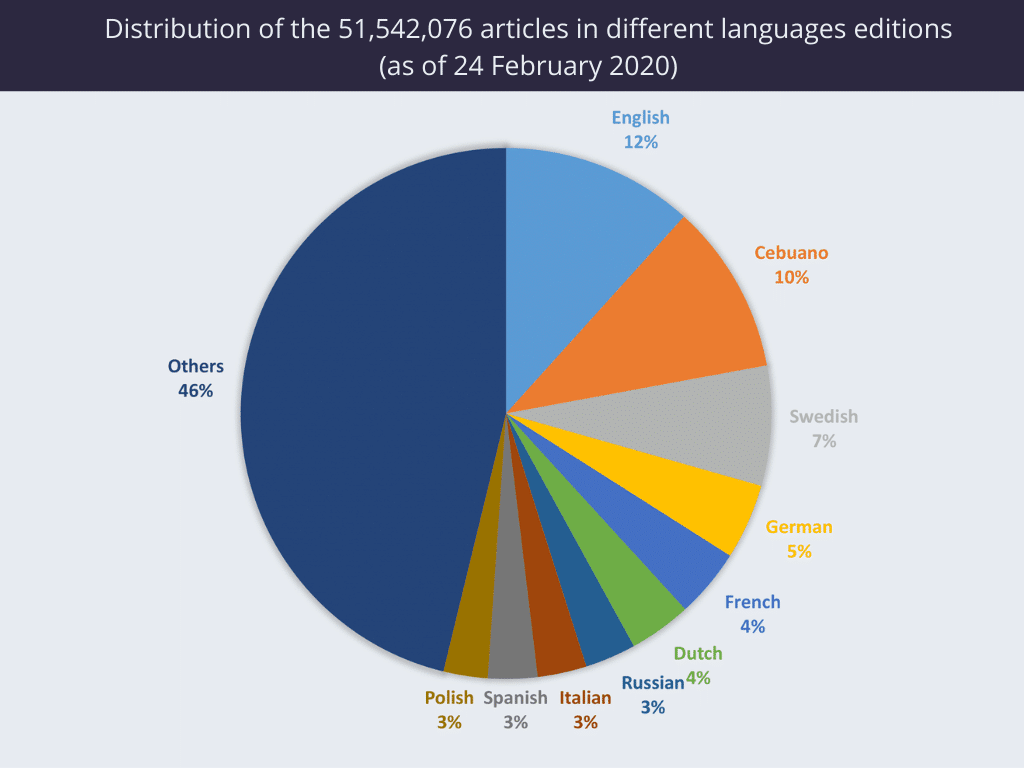
Figure 1: Relative number of wikipedia articles by language
The two biggest non-english languages on wikipedia is Cebuano (language from Philippines) & Swedish. How come? Because the contributor Sverker Johansson (Swedish with wife from Philippines) has written a bot for automatic article generation in these languages, by constructing sentences augmented with data from data bases, e.g.
The average giraffe is [height] meters tall and weighs [mass] kg.
i.e. data not good for training NLP.
3. Web scraping
To train a sentiment classifier we need text (typically a review) + score / emoticon (thumbs-up/down). Some suggestions on reviews that can be found online in any language:
- restaurants, hotels (yelp?), rental agencies
- film, books, store products
- apps, software,
- videos, music
- social media
- services: healthcare, construction, education
- user reviews on auction sites / market places
This resource on how to avoid bot detection when web-scraping might also prove useful.
- Update : “Crawlee is a web scraping and browser automation library”
- Update : New article on web scraping from Hacker News here
- Update : Use LLMs to crawl, chunk, and vectorize any websites
3.1. Google maps
Google maps collects a lot of reviews for all kinds of establishments, like restaurants, hotels, parks, landmarks, continents, and weirder things.
There seems to be many options for web scraping, but so far I have not found any way of doing it for free. The available options:
- Google Maps Places API
- Google provides their own API that is supposedly very straightforward to use, and well documented, it’s a pay-as-you-go pricing model.“
- Google Maps Scraper
github repo that extracts reviews from a file
urls.txtcontaining coordinates. I.e. the problem is now to compile the csv-file with locations. Useage:python scraper.py --N 50 -i url_input_file.txt
generates a csv file containing last 50 reviews of places present in urls.txt
- Google Maps Crawler
- From company botsol offer free trial before you buy.
- Octoparse
- Third party scraping “made easy” (no coding needed). Offers 14 days free trial. Tutorial here for scraping data in google maps, and template here.
- Apify
- module can scrape map at different zoom levels: country, state, city. But must run on their platform? Can also scrape instagram, facebook, etc. There’s a free tier “developer” package.
- Google Map Extractor
- From Ahmadsoftware. Made to find business leads, extracts rating (but not review text?), only windows?
3.2. Google apps reviews
3.3. Manual webscraping
There are a number of ways to do web scraping using python.
3.3.1. BeautifulSoup
Easiest, for me, and most bare bone is using BeautifulSoup. See documentation, and/or tutorials, I’ve found useful e.g.:
- Web Scraping 101 with Python & Beautiful Soup — No real code example, just general best practices when webscarping.
- How to scrape websites with Python and BeautifulSoup — Get up and running fast
- Intro to Beautiful Soup — Longer, if need be
3.3.2. Selenium
For fancy webpages, that rely on javascript shenanigans, such that you have to interact with it to get the data, e.g. scroll or click to activate elements, selenium is the tool to use, as it’s basically a headless browser, with which you can simulate this. There are interesting tutorial:
- Scraping Google Maps reviews in Python, uses selenium and BeautifulSoup, for scraping Gmaps, assuming you already have the url to the location.
- SeleniumBase looks very interesting, e.g. for visualizing the browser commands and visual testing.
- Also, see this discussion on scraping google maps with selenium on reddit (assumes one already has the site/url to scrape).
3.3.3. Scrapy
Scrapy has all the bells and whistles. One defines various classes that then are loaded by spacy. I spent some time reading the documentation, but there were too high threshold to get over just to start using it, compared to what I had in mind. Probably worth the time investment if one embarks on a larger web scraping endeavour.
Update : Tutorial here, featured on hacker news.
3.4. The Final Cleansing
Often web scraped reviews/pages can be “polluted” by foreign language, i.e. Norwegian reviews typically contain also Danish, Swedish and English (Or worse: the language has two different ways of writing: bokmål and nynorks).
For example, the bokelskere-set has the following distribution:
| Language | Records | Relative |
|---|---|---|
| Norwegian - bokmål | 184651 | 0.853 |
| Norwegian - nynorsk | 21004 | 0.097 |
| English | 7174 | 0.033 |
| Danish | 2459 | 0.011 |
| Swedish | 1229 | 0.006 |
This can be filtered out using e.g. polyglot. For Norwegian, and evaluate the below function once, to download the needed resources:
from polyglot.downloader import downloader from polyglot.text import Text from polyglot.detect import Detector def download_polyglot(): "Helper function with examples for downloading the resources we need" print(downloader.download_dir) print(downloader.default_download_dir()) # show supported modules for language print(downloader.supported_tasks(lang="en")) # check which languages are supported in sentiment analysis print(downloader.supported_languages_table(task="sentiment2")) # show downloaded packages from polyglot print(downloader.list(show_packages=False)) # download: downloader.download("embeddings2.en") # Download Norwegian, bokmaal & nynorsk; & English downloader.download("sentiment2.no", quiet=False) downloader.download("sentiment2.nn", quiet=False) downloader.download("sentiment2.en", quiet=False) for model in ['sentiment2', 'embeddings2', 'ner2']: for lang in ['no', 'nn', 'en']: downloader.download(f"{model}.{lang}", quiet=False)
Then we can apply the following filter on a pandas data frame:
def filter_norwegian(df): """Return masks for norwegian: bokmaal, and nynorsk Parameters ---------- df: PandasSeries Column of review text Returns ------- no: PandasSeries Masking column for bokmaal, Boolean nn: PandasSeries Masking column for nynorsk, Boolean """ # Filter out non-norwegian # df['lang'] = df.text.apply(lambda x: Detector(x).language.code) l = [] for t in df.values: try: l.append(Detector(t, quiet=True).language.code) except Exception as e: l.append(np.nan) print(e) print(t) lang = pd.DataFrame(l) print(lang.value_counts()) nn = lang.apply(lambda x: x == 'nn') # nynorsk no = lang.apply(lambda x: x == 'no') # bokmaal return no, nn
4. Tokenizers
4.1. General
Summary of summary:
- BPE counts the frequency of each word in the training corpus. It then begins from the list of all characters, and will learn merge rules to form a new token from two symbols in the vocabulary until it has learned a vocabulary of the desired size (this is a hyperparameter to pick).
- Byte-level BPE by operating on byte level, no
<UNK>tokens are needed, and more compact/efficient than BPE. - WordPiece the difference to BPE is that it doesn’t choose the pair that is the most frequent but the one that will maximize the likelihood on the corpus once merged. It’s subtly different from what BPE does in the sense that it evaluates what it “loses” by merging two symbols and makes sure it’s worth it.
- Unigram Instead of merging to form words, it starts with words and splits. not used directly, only a part of SentencePiece
- SentencePiece deal with not all languages separate words with space. Used in ALBERT and XLNet.
4.2. Transformer libraries
- github.com/huggingface/tokenizers (in Rust, bindings in Python)
- “You can either use a pre-trained tokenizer or train your own tokenizer”
- Blog-post: Hugging Face Introduces Tokenizers
- Supports:
BPETokenizer,ByteLevelBPETokenizer,SentencePieceBPETokenizer,BertWordPieceTokenizer
- github.com/glample/fastBPE
- github.com/VKCOM/YouTokenToMe
- github.com/google/sentencepiece
5. Learning BERT (PyTorch only)
BERT originates from Google, and the first models are available in TensorFlow, e.g. “Fine-tuning a BERT model” (colab), but due to my own preference for PyTorch over TensorFlow (TF), I’ve mainly been playing with the huggingface library which is the main implementation for transformer models, in python.
For theoretical/visual tutorial, Jay Alammar’s blog posts are the “must reads”, e.g.
Recently, there was a paper published on arXive (via Hacker news discussion):
5.1. 0. Minimal BERT example
The huggingface tutorial starts simple with the smallest possible code sample for BERT for sentiment analysis by using pre-trained English model, without fine-tuning:
from transformers import pipeline nlp = pipeline("sentiment-analysis") for s in ["I despise you", "I've taken a liking to you"]: result = nlp(s)[0] print(f"label: {result['label']}, with score: {round(result['score'], 4)}")
It’s worth also looking into the following HuggingFace resources:
- tokenizer summary (Excellent. Covers Byte-Pair, WordPiece, Unigram)
- quick tour (minimal example)
- training/fine-tune + links in article
- pre-processing
5.2. 1. Chris McCormick’s tutorial
The best hands-on tutorial using huggingface is Chris McCormick’s tutorial, also available as video. It’s very similar in structure, and excellent to do after, PyTorch From First Principles.
It follows the PyTorch way, by implementing optimizer, scheduler, data
loader, i.e. quite verbose but clear, compared to the more recent new way
of relying on torch.Train(). He makes use of BertTokenizer and
BertForSequenceClassification.
The dataset is The Corpus of Linguistic Acceptability (CoLA). It’s a set of sentences labeled as grammatically correct or incorrect, i.e. binary single sentence classification.
Also worth looking into his tutorial on BERT word embeddings, compare to “normal” embedding, using just a single auto-encoder layer, but in BERT we have 12+1 (“+1” due to input embedding layer), so how should a word be represented? Different layers encode different kind of information.
There is a library, bert-as-service, that already extracts word embedding from BERT in “smart way”:
…uses BERT as a sentence encoder and hosts it as a service via ZeroMQ, allowing you to map sentences into fixed-length representations in just two lines of code.
Spoiler: average embedding for each word piece (sub word token) that makes up the word, typically in the second to last layer. Also, note: words are not uniquely represented, i.e. “river bank” and “money bank”.
5.3. 2. Getting SH*T done with PyTorch
The next logical BERT-tutorial in the order is from the free online book Getting things done with PyTorch, specifically the chapter “Sentiment Analysis with BERT and Transformers by Hugging Face using PyTorch and Python”.
This is interesting, since he doesn’t use the
BertForSequenceClassification model (a normal Bert + linear layer on
top), like McCormick & co, but rather he uses the bare bones language model
found in BertModel and then wraps it manually in a PyTorch model class,
where he extracts the parameters from the last pooling-layer of
BertModel, and connect that to a fully connected layer on top.
Code sample:
from torch import nn from transformers import BertModel class SentimentClassifier(nn.Module): """Note that we are returning the raw output of the last layer since that is required for the cross-entropy loss function in PyTorch to work. Will work like any other PyTorch model """ def __init__(self, n_classes): super().__init__() self.bert = BertModel.from_pretrained(PRE_TRAINED_MODEL_NAME) # dropout for regularization: self.drop = nn.Dropout(p=0.3) # fully connected for output self.out = nn.Linear(self.bert.config.hidden_size, n_classes) def forward(self, input_ids, attention_mask): _, pooled_output = self.bert( input_ids=input_ids, attention_mask=attention_mask) output = self.drop(pooled_output) return self.out(output) # Can now use it like any other PyTorch model model = SentimentClassifier(len(class_names)) model = model.to(device)
5.4. 3. Other/Misc BERT tutorials
5.4.1. 3.1 Testing multiple models, and 16 bit floats
A Hands-On Guide To Text Classification With Transformer Models (XLNet, BERT, XLM, RoBERTa)
- Fine tune BERT testing multiple models,
BertForSequenceClassification,XLMForSequenceClassification,RobertaForSequenceClassification - Code is messy, and in addition depends on external files, from previous tutorials.
- Data set it Yelp review, (& src on colab)
- Interesting is he uses
apex import amp, from Nvidia’s mixed precision library, to shift tofp16for reduced memory footprint and speed up fine-tuning runs
5.4.2. 3.2 Intent classification tutorial & quick view of BERT’s layers
BERT for dummies — Step by Step Tutorial (colab)
Doesn’t do sentiment classification, but rather intent classification
(but still using the BertForSequenceClassification model). Use case is
to find the intent of a search query. Data set is ATIS, (Airline Travel
Information System), which consists of 26 highly imbalanced classes, that
are augmented using SMOTE algorithm, (but fails). The tutorial depends on
previous article fro reading in the ATIS data.
They use an LSTM for null-hypothesis testing, to benchmark the BERT model against. (Same author also did a tutoral using the same data set, called Natural Language Understanding with Sequence to Sequence Models)
Explores the components of the BertForSequenceClassification model:
We can see the
0BertEmbeddinglayer at the beginning, followed by a Transformer architecture for each encoder layer:BertAttention,BertIntermediate,BertOutput. At the end, we have theClassifierlayer.
For some reason this tutorial also demonstrates using the pad_sequences
from keras.preprocessing.sequence to pad the sequences, rather then
using the tokenizer’s padding option.
5.4.3. 3.3 Using Simpletransformer package
Simple Transformers — Introducing The Easiest Way To Use BERT, RoBERTa, XLNet, and XLM
Author of the python package simpletransformers demonstrates how to use
it, on the Yelp review data set for sentiment analysis.
It seems to hide too much under the hood, for my taste, but might be interesting for people interested in minimal code / maximum code wrapping.
5.4.4. 3.4 Using TorchText with tokenizer
BERT Text Classification Using Pytorch (Main code colab & processing colab)
This tutorial has pretty clean/straight forward code. It does text
classification on the kaggle REAL and FAKE News dataset (i.e. will use
BinaryCrossEntropy loss function). What might be of interest here is it
uses TorchText to create Text Field (news article) and the Label Field
(target), and how to let it know to use the BERT tokenizer, rather than
build its own vocabulary:
from torchtext.data import Field, TabularDataset, BucketIterator, Iterator # In order to use BERT tokenizer with TorchText, we have to set use_vocab=False and tokenize=tokenizer.encode text_field = Field(use_vocab=False, tokenize=tokenizer.encode, lower=False, include_lengths=False, batch_first=True, fix_length=MAX_SEQ_LEN, pad_token=PAD_INDEX, unk_token=UNK_INDEX) label_field = ... fields = [('label', label_field), ('title', text_field), ('text', text_field), ('titletext', text_field)] train, valid, test = TabularDataset.splits(path=source_folder, train='train.csv', validation='valid.csv', test='test.csv', format='CSV', fields=fields, skip_header=True)
Also does a minimal wrapping of BERT in it’s own class, and also implements saving/loading of checkpoints:
class BERT(nn.Module): def __init__(self): super(BERT, self).__init__() options_name = "bert-base-uncased" self.encoder = BertForSequenceClassification.from_pretrained(options_name) def forward(self, text, label): loss, text_fea = self.encoder(text, labels=label)[:2] return loss, text_fea
5.4.5. 3.5 “Lost in translation - Found by transformer”
Lost in Translation. Found by Transformer. BERT Explained.
This is simply a re-hashing of Jay Alammar’s famous blog post “The Illustrated Transformer”.
5.5. 4. Using new Trainer() method
New PyTorch method that abstracts away a lot of the boilerplate code for training loop. All functionality is still available through arguments.
See section Multilanguage BERT for tutorial that uses it.
5.6. 5. Use Auto class for easier experimentation
Using the Auto tool of PyTorch it automatically selects the correct class
for the model and tokenizer we want to use, by simply specifying the
model_name.
from transformers import AutoTokenizer, AutoModel
On using the Auto class, for easier model experimentation Automatic Model Loading using Hugging Face
Also covered by in the quicktour.
6. Non-English BERT
In the following, we explore the options available for using BERT on non-English languages
6.1. Multi-language BERT (mBERT)
In regard to multilanguage BERT’s performance on small languages, BotXO, said the following in an interview:
The multilingual model performs poorly for languages such as the Nordic languages like Danish or Norwegian because of underrepresentation in the training data. For example, only 1% of the total amount of data constitutes the Danish text. To illustrate, the BERT model has a vocabulary of 120,000 words, which leaves room for about 1,200 Danish words. Here comes BotXO’s model, which has a vocabulary of 32,000 Danish words.
- Google Research has a multilanguage BERT is trained on 104 languages.
- Hugging face has transformer models BERT, XLM, and XLM RoBERTa for
multilanguage use, with the following checkpoints:
bert-base-multilingual-uncased102 languagesbert-base-multilingual-cased104 languagesxlm-roberta-base100 languages, outperforms mBERTxlm-roberta-large100 languages, outperforms mBERT
(I do not yet have results when running these models)
6.2. LASER — Language-Agnostic SEntence Representations (facebook)
From facebook (blog, github) built on PyTorch, to do zero-shot transfer of NLP models from one language, such as English, to scores of others.
LASER sets a new state of the art on zero-shot cross-lingual natural language inference accuracy for 13 of the 14 languages in the XNLI corpus.
- Trained on 93 languages, all using the same BiLSTM encoder
- (…but tokenizer is language specific)
- Is trained on sentence-paris from different languages, to embed all languages jointly in single shared space.
https://engineering.fb.com/ai-research/laser-multilingual-sentence-embeddings/
On of the tasks of interest might be Application to cross-lingual document classification where they train a classifier on English, then apply to several other languages. However, most other applications for the model seems to be measuring distance in embedded space between same sentence in different languages, or similar.
6.3. LaBSE — Language-Agnostic BERT Sentence Embedding (google)
From Google (arXiv, blog), in TF2 available on tfhub. The blog post stats that accuracy decreases slowly with more languages added.
Idea is to leverage small corpus languages by multi language embedding:
… cross-lingual sentence embeddings for 109 languages. The model is trained on 17 billion monolingual sentences and 6 billion bilingual sentence pairs …resulting in a model that is effective even on low-resource languages for which there is no data available during training … interestingly, LaBSE even performs relatively well for many of the 30+ Tatoeba languages for which it has no training data (see below)
It can do various translations / sorting of translation matches.
(I do not have results on running this on any tasks)
6.4. TODO BotXO models (Nordic BERT models)
BotXO.ai is a danish company (that develops chat bots?), that have trained their own Nordic BERT models (interview) using google TPUs, and common crawl data:
- Norwegian BERT Trained on 4.5 GB text.
- Danish BERT Trained on 9.5 GB text.
- Swedish BERT Trained on 25 GB text.
- models on their github github.com/botxo/nordic-bert
Next, to load these models, I’ve explored using the native TensorFlow-way (equals pain), and then PyTorch. The pre-trained model checkpoints contain the following files:
bert_config.json bert_model.ckpt.data-00000-of-00001 bert_model.ckpt.index bert_model.ckpt.meta vocab.txt
6.4.1. Loading models using Tensorflow (and giving up)
To load a model, follow general instructions google-research/bert (e.g. on GLUE-test data downloaded with script). I start with downloading their models, to make sure they work, but I ran into the following issues:
- Requires TF between v1.15 and v1.11 –> must downgrade TF
pipfor that TF version requires python <= v3.6 –> must downgrade python. I.e. I usepython -m venvas described in previous post, with requirements:tensorflow==1.15.0 tensorflow-gpu==1.15.0
- Once this has been fixed, it cannot run on GPU, since the libcudnn library is incompatible with the pip-installed TF version. One must also install CUDA 10.1 or 10.0, and matching version of cuDNN. (Available in Arch linux User Repository).
- TF is very particular (read: retarded) with file paths. It can not
find model file in “path”, even when the “path” is returned correctly in
the error message. To fix:
- When/if using relative path, one must explicitly use “here”, i.e. prefix
folder with
./ - Don’t use
~/instead write out the full path:/home/me/
- When/if using relative path, one must explicitly use “here”, i.e. prefix
folder with
Also, I read through the documentation of Bert-chainer library, but I don’t currently understand what the exact benefit is (older attempt to do the same thing as Keras?), but they state:
- “This implementation can load any pre-trained TensorFlow checkpoint for BERT”
- “You can convert any TensorFlow checkpoint for BERT (in particular the pre-trained models released by Google) in a Chainer save file by using the converttfcheckpointtochainer.py script.”
Either way, at this point I gave up and shifted to just converting the model to PyTorch.
6.4.2. Loading model using PyTorch
Trying to load these models using native TF, is just causing an endless chain of headache. Instead, we can convert the model to PyTorch, and we don’t need to downgrade anything, it just works.
The conversion script is part of transformers-cli since 2.3.0. (needs
both TensorFlow and PyTorch). Example applied to google’s models:
export BERT_BASE_DIR=/home/me/uncased_L-12_H-768_A-12 transformers-cli convert --model_type bert \ --tf_checkpoint $BERT_BASE_DIR/bert_model.ckpt \ --config $BERT_BASE_DIR/bert_config.json \ --pytorch_dump_output $BERT_BASE_DIR/pytorch_model.bin
- Note-1, for
tf_checkpointwe must not only give folder path to TF checkpoint, but also stem/base name of the checkpoint (bert_model.ckpt). Resulting model is less then half the size of the TF model. - Note-2, might/must rename the
bert_config.jsonto justconfig.json, for transformers loading to find the model
Test that it worked, we can use frompretrained to load the local model
import torch from transformers import BertModel, BertTokenizer PATH = "./models/uncased_L-12_H-768_A-12/" # google-bert model # PATH = "./models/norwegian_bert_uncased/" # BotXO model tokenizer = BertTokenizer.from_pretrained(PATH, local_files_only=True) model = BertModel.from_pretrained(PATH) # TEST tokenizer: sample_txt = "How are you doing to day, sir?" tokens = tokenizer.tokenize(sample_txt) print(tokens) print(tokenizer.convert_tokens_to_ids(tokens))
Complication: Tokenizer in Norwegian only yields [UNK] tokens (see issue #9).
Comparing vocab.txt with the converted google bert-uncased model, we see
difference in how segments starting a word are denoted:
- Engilish: No space token, and suffix tokens prefixed with
## - Norwegian: All tokens prefixed with
##and space token_, thus suffix tokens lack space token as first symbol.
| English | Norwegian |
|---|---|
| [PAD] | [PAD] |
| [unused0] | [UNK] |
| [unused98] | [CLS] |
| [UNK] | [SEP] |
| [CLS] | [MASK] |
| [SEP] | ##er |
| [MASK] | ##en |
| [unused99] | ##s |
| [unused100] | ##et |
| [unused101] | ##for |
| [unused993] | ##ing |
| the | ##det |
| of | ##te |
| and | ##av |
| in | ##på |
| to | ##de |
| was | ##som |
| he | ##at |
| is | ##med |
| as | ##opp |
| for | ##ker |
| on | ##ang |
| with | ##du |
| that | ##men |
| ##s | ##ett |
| she | ##re |
| you | ##sel |
| ##ing | ##man |
Above problem can be fixed by:
# Load vocab version with "##_"-prefix removed: tokenizer = BertTokenizer.from_pretrained(PATH, local_files_only=True, vocab_file=PATH+"/vocab_clean.txt")
I’ve also tried doing the swap in place, the vocab gets updated, but still encodes all tokens to [UNK]
def fix_norwegian_vocab(tokenizer): "Start of word tokens prefixed with '##_' -> remove it!" import re import collections # The special '_'-like char is unicode: 0x2581 # use M-x describe-char in emacs underscore = "\u2581" d = {re.sub(r'##' + underscore, "", key): item for key, item in tokenizer.vocab.items()} d = collections.OrderedDict(d) tokenizer.vocab = d return tokenizer
6.5. Swedish royal library BERT
- The Swedish royal library has trained multiple models (currently 5), both BERT and ALBERT; available on their github, described in paper.
- GPT-2 generated Karin Boye (swedish) poems
7. TODO Pre-training BERT (training from scratch)
There are many pre-trained BERT models available, both from huggingface but also from the community; there’s an untested electra-base (Google’s ELECTRA TF model src here), which could be used for text classification, among other things.
Pre-training is done once per language/model and takes a couple of days on a cluster of TPUs in the cloud. Fine-tuning is then done in under 1 hour on a single cloud TPU (64GB RAM), (see fine-tuning on TPU), or a few hours on GPU, according to google.
To consider regarding performance:
Longer sequences are disproportionately expensive because attention is quadratic to the sequence length. In other words, a batch of 64 sequences of length 512 is much more expensive than a batch of 256 sequences of length 128. The fully-connected/convolutional cost is the same, but the attention cost is far greater for the 512-length sequences. Therefore, one good recipe is to pre-train for, say, 90,000 steps with a sequence length of 128 and then for 10,000 additional steps with a sequence length of 512. The very long sequences are mostly needed to learn positional embeddings, which can be learned fairly quickly. Note that this does require generating the data twice with different values of
max_seq_length.
Note, Google AI recently posted on how to improve the quadratic scaling of transformers for long range attention: Rethinking Attention with Performers, by introducing the Performer, an attention mechanism that scales linearly.
7.1. Data size?
Question is how much data is needed to train a transformer model? GPT-2 (82M parameters) is trained on wikiText-103 (100M tokens, 200k vocab).
There are examples of fine-tuning on 900k tokens & 10k vocabulary, or 100M
tokens and 200k vocabulary. Generally, typical values for VOC_SIZE are
somewhere in between 32000 and 128000, and 100M lines is sufficient for
reasonable sized BERT-base (according to blog).
SpaCy writes in a blog post, (about interfacing with huggingface), that “Strubell (2019) calculates that pretraining the BERT base model produces carbon emissions roughly equal to a transatlantic flight.”
7.2. Tensorflow
Tensorflow-models, can be converted to PyTorch, if that is preferable. Using TF, to pre-training from scratch, google writes:
our recommended recipe is to pre-train a BERT-Base on a single preemptible Cloud TPU v2, which takes about 2 weeks at a cost of about $500 USD (based on the pricing in October 2018). You will have to scale down the batch size when only training on a single Cloud TPU, compared to what was used in the paper. It is recommended to use the largest batch size that fits into TPU memory.
Also of interest:
- TPU-pricing
- Training on TPUv2 took ~54h for this tutorial, but google will terminate running colab notebooks every ~8h, so need pre-paid instance.
General:
- Input data file needs to be as shard, since it stores all at once in memory
- The input is a plain text file, with one sentence per line. Documents are
delimited by empty lines. The output is a set of
tf.train.Examplesserialized into 0TFRecord= file format.
Resources and tutorials to keep in mind:
- TF: Text Classification with Movie Reviews
- Blog: Pre-training BERT from scratch with cloud TPU (code)
github: SentencePiece
SentencePiece supports two segmentation algorithms, Byte-Pair-Encoding (BPE) and unigram language model. … SentencePiece allows us to make a purely end-to-end system that does not depend on language-specific pre/postprocessing. … Fast and lightweight.
7.3. TODO PyTorch
If we want to train a new model from scratch, e.g. a new language, there’s
a huggingface tutorial for Esperanto that is useful. The model size is
comparable to DistilBERT (84M parameters = 6 layers x 768 hidden, 12
attention heads) trained on 3GB dataset (oscar + Leipzig). The tutorial is
mirrored in a colab version (git), as that makes use of the new PyTorch
Trainer() method, rather than as a running the training as scrip from the
command line with long string of arguments.
In spite of the model being relatively small, on my Nvidia GPU (GeForce GTX 1050 Ti Mobile) it would take 40h to train a single Epcoh of 1M Esperanto sequences, in batches of 8 (reduce from default 64, to fit on 4GB GPU RAM).
The following from the tutorial caused me some head scratching:
“We choose to train a byte-level Byte-pair encoding tokenizer (the same as GPT-2), with the same special tokens as RoBERTa. Let’s arbitrarily pick its size to be 52,000. We recommend training a byte-level BPE (rather than let’s say, a WordPiece tokenizer like BERT) because it will start building its vocabulary from an alphabet of single bytes, so all words will be decomposable into tokens (no more <unk> tokens!).”
Stuff I’m currently reading:
- NVIDIA NeMo “Make sure you have
nemoandnemo_nlpinstalled before starting this tutorial.” NeMo is a framework-agnostic toolkit for building AI applications powered by Neural Modules. Current support is for PyTorch (minimum v.1.4) framework. - “Multi Class Text Classification With Deep Learning Using BERT Natural Language Processing, NLP, Hugging Face” (probably copy-paste of McCormick’s blog) https://towardsdatascience.com/multi-class-text-classification-with-deep-learning-using-bert-b59ca2f5c613 git - notebook
8. Beyond BERT
Overview of other transformer / post-BERT models.
8.1. Huggingface transformer models
There is more then just BERT to the huggingface library of pretrained transformer-models. Here’s a short summary of (the summary of) the models I found interesting in my quest for text classification.
Note that the only difference between autoregressive models (e.g. GPT) and autoencoding models (e.g. BERT) is in the way the model is pretrained.
- BERT
- Models:
bert-base-uncased
- Models:
- ALBERT (A lite BERT …)
- Smaller embedding layer, than hidden layer (E << H)
- Group layers that share weights (save RAM)
- Models:
albert-base-v1
- RoBERTa > BERT - A Robustly Optimized BERT Pretraining Approach
- Better optimized hyperparameters compared to BERT
- Same implementation as BertModel with a tiny embeddings tweak as well as a setup for RoBERTa pretrained models
- RoBERTa shares architecture with BERT, but uses a byte-level BPE as a tokenizer (same as GPT-2) and uses a different pre-training scheme.
- RoBERTa doesn’t have
token_type_ids, - Models:
distilroberta-base
- DistilBERT Destilled BERT. A faster lighter cheaper version of BERT.
- Same implementation, derived from a pre-trained BERT
- Significantly fewer parameters.
- Models:
distilbert-base-uncased,distilbert-base-multilingual-cased
- mBERT Multilingual BERT, see above
- XLM Cross-lingual Language Model Pretraining (arXiv)
- On top of positional embeddings, the model has language embeddings
- Three different checkpoints (for three different types of training)
- Causal language modeling (CLM)
- Masked language modeling (MLM) (like RoBERTa)
- Combined MLM & Translation language modeling (TLM)
- Models:
xlm-mlm-100-1280trained on 100 langauges
- XLM-RoBERTa
- Uses RoBERTa tricks on the XLM approach, sans TLM
Doesn’t use the language embeddings, so it’s capable of detecting the input language by itself.
Our model, dubbed XLM-R, significantly outperforms multilingual BERT (mBERT) on a variety of cross-lingual benchmarks“… This implementation is the same as RoBERTa
- Models:
xlm-roberta-base
- XLNet Generalized Autoregressive Pretraining for Language Understanding
- Huggingface documentation
- Has no sequence length limit
- Models:
XLNetForSequenceClassification,XLNetForMultipleChoice,XLNetForTokenClassification
8.2. State of the art
There are many models that go beyond BERT, and out perform it on bench marks. Some of interest might be:
- XLNet (Google), Generalized Autoregressive Pretraining for Language Understanding
- uses “transformer-XL” (better at handling long complicated sentences)
- does the word-masking in training differently to BERT (shuffled)
- Autoregressive (like GPT-1/2), i.e. good at generating new text, rather than autoencoder, which are good at reconstructing learned text, as BERT
- Is implemented in Huggingface, doc
- ERNIE (Baidu), Enhanced Representation through Knowledge Integration, record breaking general language model, by also including knowledge about the world.
- ERNIE 2.0 “Experimental results demonstrate that ERNIE 2.0 outperforms BERT and XLNet on 16 tasks
- Language-Agnostic BERT Sentence Embedding (google) as covered previously above .